CASIA Handwritten Chinese Character Recognition Using Convolutional Neural Network and Similarity Ranking (with TensorFlow Source Code)
-
Additional Sources:
Source code (implemented by Tensorflow) for this article is available at Github: Go to Github.
Dataset for this article is available at CASIA: Go to CASIA.

Abstract:
Convolution Neural Networks (CNN) have recently achieved state-of-the art performance on handwritten Chinese character recognition (HCCR). However, most of CNN models employ the SoftMax activation function and
minimize cross entropy loss, which may cause loss of inter-class information. To cope with this problem, we propose to combine cross entropy with similarity ranking function and use it as loss function. The
experiments results show that the combination loss functions produce higher accuracy in HCCR. This report briefly reviews cross entropy loss function, a typical similarity ranking function: Euclidean distance,
and also propose a new similarity ranking function: Average variance similarity. Experiments are done to compare the performances of a CNN model with three different loss functions. In the end, SoftMax cross
entropy with Average variance similarity produce the highest accuracy on handwritten Chinese characters recognition.
Keywords:
Convolution Neural Networks (CNN); handwritten Chinese character recognition (HCCR); cross-entropy function; similarity ranking function
I. INTRODUCTION
This report is focused on the offline Handwritten Chinese character recognition, which is an important research field in pattern recognition. Recognizing Chinese characters is more challenging compared with alphabet and digits recognition. Because Chinese has over 7000 classes in the common vocabulary, and it also has more complex structure in each character. In recent years, Chinese handwriting character recognition has received much research and attention. As regular Neural network don't scale well to full image, in order to deal with the handwritten images, the most suitable approach is to use convolution neural network (CNN). The model in this report is based on CNN. However, unlike most existing methods, the method presented in this report using both classification and similarity ranking signals as supervision to train a CNN model. Classification is to classify an input image into a large number of identity classes, while similarity ranking is to minimize the intra-class distance while maximizing the inter-class distance.
The rest of this report includes the briefly reviews for convolutional neural network and cross-entropy, introduction of similarity ranking function, methodology of the experiment and the results analysis.
II. BACKGROUND
2.1 Convolutional Neural Network
Convolutional neural networks (CNNs) consist of an input and an output layer, as well as multiple hidden layers. The hidden layers of a CNN typically consist of convolutional layers, pooling layers, fully connected layers and normalization layers [1]. Avoiding complex pre-processing of the image (extracting artificial features, etc.), CNNs process input original image directly. The layers of a CNN have neurons arranged in 3 dimensions: width, height and depth, CNN can reduce the full image into a single vector of class scores, arranged along the depth dimension through complete process [2]. In visual object recognition, CNNs often achieve a good performance. The convolution layer only increases the depth and leave the height and width unchanged. For the pooling layer, it would keep the depth, and narrow the size of volume. Finally, the fully connected layer would transform the volume into 1x1xn which n is represented to different classes [3]. Unlike the regular neural networks, CNN preserves the input's neighborhood relations and spatial locality in their latent higher-level feature representations. While the architecture of common fully connected neural network do not scale well to realistic-sized high-dimensional images in terms of computational complexity, CNNs do, since the number of free parameters describing their shared weights does not depend on the input dimensionality [4].
2.2 Loss Function for Classification Problems
2.2.1 Entropy
Entropy is a measure for information contents and could be defined as the unpredictability of an event. Assume that the probability of an event occurring is p, then the unpredictability of this event is log2(1/p) * log2(1/p) [5]. So, the greater the probability is, the smaller the unpredictability is, which means the information contents is also very small. If an event occurs inevitably with the probability of 100%, then the unpredictability and information content are 0.
Assume that a non-uniform dice, the probability of rolling it to get a definite point X ( X={x1,x2,...,x6} ) is Pi = p(X=Xi). The expectation of the discrete random variable can be defined as [5]:
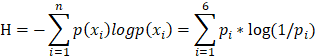
The expectation H is entropy. So, the greater the entropy is, the greater the unpredictability is.
2.2.2 Cross-entropy
For same event, p is the real probability density, while q is the probability density from a prediction model. Cross-entropy can be defined as [6]:
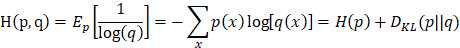
2.2.3 Cross-entropy Used as Loss Function
In machine learning and deep learning, cross-entropy can be used to define loss function. It represents the inaccuracy of predictions.
Considering a binary classification problem. There are only two classifications for the result of one prediction, so,
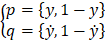
cross-entropy is:
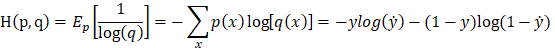
which is the loss function of logistic regression. It computes the average cross-entropy of m samples [7]:
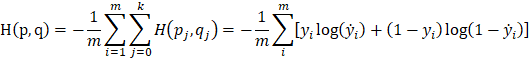
Cross-entropy can be used in multiclassification problems with the combination of SoftMax (do not consider regularization):
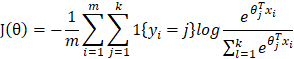
Compared with quadratic loss function, cross-entropy loss function gives better training performance on neural networks.
2.3 Similarity Ranking Function
In classification problems, besides differences in different classes, another important information can be learned is the similarities among different samples. Different similarity measurements may have impacts on the accuracy of the prediction.
2.3.1 Euclidean Distance
Euclidean Distance defines the true distance between two points in an m-dimensional space. In supervised learning, it can be used to measure the similarity between two samples with n features [8]:
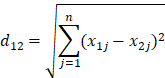
where d12 refers to the similarity between first and second samples.
2.3.2 Average Variance Similarity
In the statistical description, variance is used to calculate the difference between each sample and the mean of all samples. It is defined as:
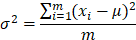
III. METHODOLOGY
The data used in this experiment is from CASIA online and offline Chinese handwriting databases. We selected data from the offline database. Original CASIA offline dataset is a list of images labeled with
corresponding Chinese character, with size 6.7GB, contains 3160 different characters and total 1055440 samples, each character has average 334 corresponding samples. Due to the limitation of our machine, we only
use a subset of the dataset, with 300 different characters and total 100342 samples. CASIA also provide offline character test dataset for evaluation, with average 81 different samples corresponding to each
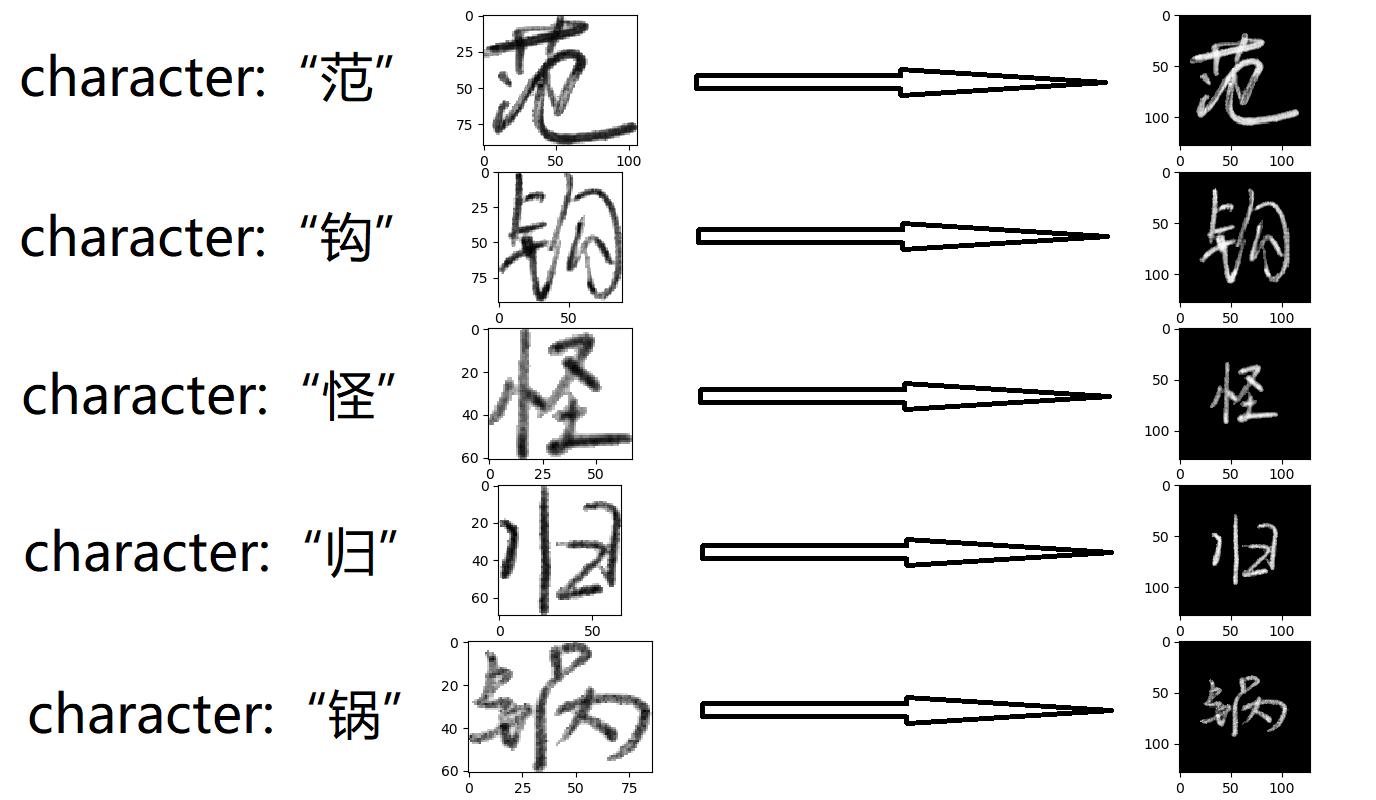
character. There are some handwriting samples from different writers shown in figure 1.
3.1 Data Preprocessing
The original CASIA dataset is in "gnt" format, which is hard for TensorFlow to process, so we transform the dataset to "sqlite" format, which is easy to access through python package "sqlite3". Because the size of
each image sample is different, so we perform cropping, scaling, and padding for each image, the result images have same size (128*128 pixels). Our group also perform normalization to the data, so the network is
easier to converge in training period. There are some images for each character after preprocess in figure 2.
import numpy as np
import tensorflow as tf
import pickle, sqlite3
import config
class DataManager:
def __init__(self):
self.label_array = pickle.load(open(config.CASIA_label_file_path, 'rb')) # train label array length = 300
self.init_dataset()
def init_dataset(self):
if (config.MODE == tf.estimator.ModeKeys.TRAIN):
self.CASIA_train_sqlite_connection = sqlite3.connect(config.CASIA_train_sqlite_file_path)
self.CASIA_train_sqlite_cursor = self.CASIA_train_sqlite_connection.cursor()
# save sample index into array
self.CASIA_train_sqlite_cursor.execute("SELECT ID,Character_in_gb2312 FROM TrainDataset")
train_dataset_index = self.CASIA_train_sqlite_cursor.fetchall()
self.train_dataset_id_array = []
self.train_dataset_character_dict = dict()
for ID, Character_in_gb2312 in train_dataset_index:
self.train_dataset_id_array.append(ID)
if Character_in_gb2312 not in self.train_dataset_character_dict:
self.train_dataset_character_dict[Character_in_gb2312] = [ID]
else:
self.train_dataset_character_dict[Character_in_gb2312].append(ID)
if (config.MODE == tf.estimator.ModeKeys.EVAL):
self.CASIA_test_sqlite_connection = sqlite3.connect(config.CASIA_test_sqlite_file_path)
self.CASIA_test_sqlite_cursor = self.CASIA_test_sqlite_connection.cursor()
self.CASIA_test_sqlite_cursor.execute("SELECT ID,Character_in_gb2312 FROM TestDataset")
test_dataset_index = self.CASIA_test_sqlite_cursor.fetchall()
self.test_dataset_id_array = []
for ID, Character_in_gb2312 in test_dataset_index:
self.test_dataset_id_array.append(ID)
# ramdom select certain amount of training data
def next_train_batch_random_select(self, batch_size=200):
select_ids = np.random.choice(self.train_dataset_id_array, batch_size, replace=False)
select_sql = "SELECT * FROM TrainDataset WHERE ID IN " + str(tuple(select_ids))
self.CASIA_train_sqlite_cursor.execute(select_sql)
select_data = self.CASIA_train_sqlite_cursor.fetchall()
feature_batch, target_batch = self.process_sqlite_data(select_data)
return feature_batch, target_batch
# ramdom select x sample in each y classes
def next_train_batch_fix_character_amount(self, character_amount=90, each_character_sample_amount=2):
select_characters = np.random.choice(self.label_array, character_amount, replace=False)
select_ids = []
for character in select_characters:
select_id = np.random.choice(self.train_dataset_character_dict[character], each_character_sample_amount,
replace=False)
select_ids.extend(select_id)
select_sql = "SELECT * FROM TrainDataset WHERE ID IN " + str(
tuple(select_ids)) + " ORDER BY Character_in_gb2312"
self.CASIA_train_sqlite_cursor.execute(select_sql)
select_data = self.CASIA_train_sqlite_cursor.fetchall()
feature_batch, target_batch = self.process_sqlite_data(select_data)
return feature_batch, target_batch
def next_test_batch(self, batch_size=200):
if len(self.test_dataset_id_array) >= batch_size:
select_ids = np.random.choice(self.test_dataset_id_array, batch_size, replace=False)
else:
select_ids = self.test_dataset_id_array
self.test_dataset_id_array = list(set(self.test_dataset_id_array) - set(select_ids))
select_sql = "SELECT * FROM TestDataset WHERE ID IN " + str(tuple(select_ids))
self.CASIA_test_sqlite_cursor.execute(select_sql)
select_data = self.CASIA_test_sqlite_cursor.fetchall()
feature_batch, target_batch = self.process_sqlite_data(select_data)
return feature_batch, target_batch
def process_sqlite_data(self, sqlite_data):
feature_batch = np.zeros(shape=(len(sqlite_data), config.image_hight, config.image_width), dtype=np.float32)
target_batch = np.zeros(shape=(len(sqlite_data), len(self.label_array)), dtype=np.float32)
for i in range(len(sqlite_data)):
# construct features
img = pickle.loads(sqlite_data[i][5])
height, width = np.shape(img)
# 1. crop by (target_image_hight * target_image_width)
if height > config.image_hight:
img = img[(height - config.image_hight) // 2:(height + config.image_hight) // 2, :]
if width > config.image_width:
img = img[:, (width - config.image_width) // 2:(width + config.image_width) // 2]
# pad to (target_image_hight * target_image_width)
height, width = np.shape(img)
top_pad = (config.image_hight - height) // 2
bottom_pad = (config.image_hight - height) // 2 + np.mod(config.image_hight - height, 2)
left_pad = (config.image_width - width) // 2
right_pad = (config.image_width - width) // 2 + np.mod(config.image_width - width, 2)
img = np.pad(img, ((top_pad, bottom_pad), (left_pad, right_pad)), 'constant', constant_values=255)
# 3. scale graylevel 255. to 0. and graylevel 0. to 1.
img = (255 - img)
img = img.astype(np.float32)
feature_batch[i, :, :] = img
# construct target
label = [int(x == sqlite_data[i][1]) for x in self.label_array]
target_batch[i, :] = label
return feature_batch, target_batch
3.2 Model design
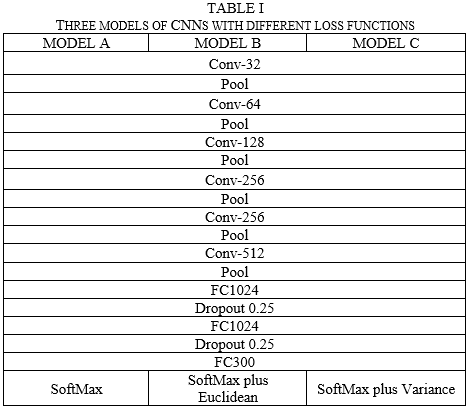
Our group designed 3 different models, all 3 models have the same neural network structure, consists of 6 convolutional layers, 6 pooling layers, 2 fully connected layers and 2 dropout layers. For each convolutional layer and fully connected layer, we use leaky Relu as activation function to speed up the training process. However, they use different loss functions respectively. Model architecture can be summarized as the table 1.
import tensorflow as tf
import config
def cnn(X, Y):
input_layer = tf.reshape(X, [-1, config.image_hight, config.image_width, 1])
# Input Tensor Shape: [batch_size, 128, 128, 1]
# Output Tensor Shape: [batch_size, 128, 128, 32]
with tf.name_scope("conv1"):
conv1 = tf.layers.conv2d(inputs=input_layer, filters=32, kernel_size=[5, 5], padding="same",
activation=tf.nn.leaky_relu)
# Input Tensor Shape: [batch_size, 128, 128, 32]
# Output Tensor Shape: [batch_size, 64, 64, 32]
with tf.name_scope("pool1"):
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# Input Tensor Shape: [batch_size, 64, 64, 32]
# Output Tensor Shape: [batch_size, 64, 64, 64]
with tf.name_scope("conv2"):
conv2 = tf.layers.conv2d(inputs=pool1, filters=64, kernel_size=[5, 5], padding="same",
activation=tf.nn.leaky_relu)
# Input Tensor Shape: [batch_size, 64, 64, 64]
# Output Tensor Shape: [batch_size, 32, 32, 64]
with tf.name_scope("pool2"):
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# Input Tensor Shape: [batch_size, 32, 32, 64]
# Output Tensor Shape: [batch_size, 32, 32, 128]
with tf.name_scope("conv3"):
conv3 = tf.layers.conv2d(inputs=pool2, filters=128, kernel_size=[5, 5], padding="same",
activation=tf.nn.leaky_relu)
# Input Tensor Shape: [batch_size, 32, 32, 128]
# Output Tensor Shape: [batch_size, 16, 16, 128]
with tf.name_scope("pool3"):
pool3 = tf.layers.max_pooling2d(inputs=conv3, pool_size=[2, 2], strides=2)
# Input Tensor Shape: [batch_size, 16, 16, 128]
# Output Tensor Shape: [batch_size, 16, 16, 256]
with tf.name_scope("conv4"):
conv4 = tf.layers.conv2d(inputs=pool3, filters=256, kernel_size=[5, 5], padding="same",
activation=tf.nn.leaky_relu)
# Input Tensor Shape: [batch_size, 16, 16, 256]
# Output Tensor Shape: [batch_size, 8, 8, 256]
with tf.name_scope("pool4"):
pool4 = tf.layers.max_pooling2d(inputs=conv4, pool_size=[2, 2], strides=2)
# Input Tensor Shape: [batch_size, 8, 8, 256]
# Output Tensor Shape: [batch_size, 8, 8, 256]
with tf.name_scope("conv5"):
conv5 = tf.layers.conv2d(inputs=pool4, filters=256, kernel_size=[5, 5], padding="same",
activation=tf.nn.leaky_relu)
# Input Tensor Shape: [batch_size, 8, 8, 256]
# Output Tensor Shape: [batch_size, 4, 4, 256]
with tf.name_scope("pool5"):
pool5 = tf.layers.max_pooling2d(inputs=conv5, pool_size=[2, 2], strides=2)
# Input Tensor Shape: [batch_size, 4, 4, 256]
# Output Tensor Shape: [batch_size, 4, 4, 512]
with tf.name_scope("conv6"):
conv6 = tf.layers.conv2d(inputs=pool5, filters=512, kernel_size=[5, 5], padding="same",
activation=tf.nn.leaky_relu)
# Input Tensor Shape: [batch_size, 4, 4, 512]
# Output Tensor Shape: [batch_size, 2, 2, 512]
with tf.name_scope("pool6"):
pool6 = tf.layers.max_pooling2d(inputs=conv6, pool_size=[2, 2], strides=2)
# Input Tensor Shape: [batch_size, 2, 2, 512]
# Output Tensor Shape: [batch_size, 2 * 2 * 512]
feature_layer = tf.reshape(pool6, [-1, 2 * 2 * 512])
return feature_layer
def full_connected_classifier(feature_layer):
with tf.name_scope("dense1"):
dense1 = tf.layers.dense(inputs=feature_layer, units=1024, activation=tf.nn.leaky_relu)
with tf.name_scope("dropout1"):
dropout1 = tf.layers.dropout(dense1, rate=0.25, training=config.MODE == tf.estimator.ModeKeys.TRAIN)
with tf.name_scope("dense2"):
dense2 = tf.layers.dense(inputs=dropout1, units=1024, activation=tf.nn.leaky_relu)
with tf.name_scope("dropout2"):
dropout2 = tf.layers.dropout(dense2, rate=0.25, training=config.MODE == tf.estimator.ModeKeys.TRAIN)
with tf.name_scope("out_layer"):
classification_layer = tf.layers.dense(inputs=dropout2, units=config.label_array_length, activation=tf.nn.leaky_relu)
return classification_layer
3.3 Validation process
Due to the limitation of our machine, we didn't perform cross validation in our experiment, all training batch is randomly selected from the training dataset. However, there is another separated validation dataset provided by CASIA, which we only use in the validation process.
For model 1(SoftMax only), we use SGD (stochastic gradient descent) with batch size 200, every sample is random selected from the whole dataset. We use SoftMax Cross Entropy as the loss function to train model 1.
SoftMax Cross Entropy can maximize the distance between different classes.
For model 2(SoftMax plus Euclidean), we use batch size 180, with 90 characters and 2 samples for each character. Later use 2 samples of same class to calculate the Euclidean distance between them, we use Euclidean
distance plus SoftMax Cross Entropy loss as the final loss function. Minimize the final loss function not only can minimize the Euclidean distance between same class, but also capable of minimize the SoftMax
Cross Entropy loss.
def calculate_euclidean(classification_layer):
character_layer_1 = tf.strided_slice(classification_layer, begin=[0, 0],
end=[character_amount * each_character_sample_amount,
config.label_array_length],
strides=[each_character_sample_amount, 1])
character_layer_2 = tf.strided_slice(classification_layer, begin=[1, 0],
end=[character_amount * each_character_sample_amount,
config.label_array_length],
strides=[each_character_sample_amount, 1])
#discance between 2 image
loss = tf.pow(tf.nn.l2_loss(character_layer_1 - character_layer_2), 0.5)
return loss
For model 3(SoftMax plus variance), we use batch size 200, with 5 characters and 40 samples for each character. Later use 40 samples of same class to calculate the variance for each class, we use variance plus
SoftMax Cross Entropy loss as the final loss function. Minimize the final loss function not only can minimize the variance between same class, but also capable of minimize the SoftMax Cross Entropy loss.
def calculate_variance(classification_layer):
character_layer = tf.reshape(classification_layer,
shape=[character_amount, each_character_sample_amount, config.label_array_length])
#variance in all same class image
character_layer_mean, character_layer_variance = tf.nn.moments(character_layer, [1])
loss = tf.reduce_mean(character_layer_variance)
return loss
IV. EVALUATION AND RESULTS
This section first discusses the implementation details, then presents evaluation results comparing the proposed algorithm to 2 other competing models.
4.1 Implementation details
Our group use python package "pickle" and "sqlite" to manage dataset, which can access the database by database SQL. We implement all 3 different models with machine learning framework "TensorFlow", which is the new standard in deep learning industry. We choose "TensorFlow" because its capable of GPU acceleration. All 3 models are trained on GTX 1060 discrete GPU w/6GB GDDR5 graphics memory. It took 3 hours for model 1 to converge, and 5 hours for model 2 and model 3 to converge.
4.2 Results
After the training process, we perform evaluation process using another separated evaluation dataset. the recognition rates are applied to evaluate the accuracy of models with different loss functions. The results are shown in the table 2.
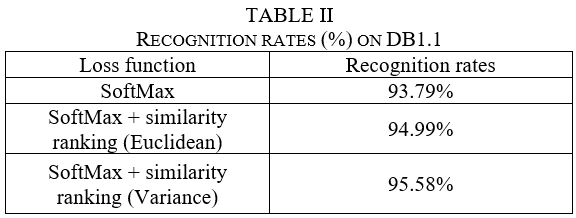
For model without the usage of similarity ranking function, the recognition rate is 93.70%. After using Euclidean as similarity ranking function, the recognition rate is up to 94.99%. After using variance as similarity ranking function, the recognition rate is up to 95.58%.
Table 2 shows that the model with similarity ranking function has a small but consistent advantage compare to model without similarity ranking function. In addition, variance similarity ranking function is better than Euclidean similarity ranking function.
V. CONCLUSION
Overall, handwritten Chinese character recognition is divided into two categories. One is online handwritten Chinese character, and the other is offline handwritten Chinese character. In this project, experiments are implemented on the dataset of offline handwritten Chinese character. This report focuses on the loss functions of a CNN model and demonstrates that the character classification and similarity ranking supervisory signals are complementary for each other, which can increase inter-class variations and reduce intra-class variations, and therefore achieve a much better classification performance. Combination of the two supervisory signals leads to significantly better results than only SoftMax cross-entropy based character classification. In addition, variance similarity ranking function have better performance than Euclidean similarity ranking function.
REFERENCES
[1] "Convolutional Neural Networks (LeNet) – DeepLearning 0.1 documentation". DeepLearning 0.1. LISA Lab. Retrieved 31 August 2013.
[2] Krizhevsky, Alex. "ImageNet Classification with Deep Convolutional Neural Networks". Retrieved 17 November 2013.
[3] "CS231n Convolutional Neural Networks for Visual Recognition". cs231n.github.io. Retrieved 2017-04-25.
[4] Le Callet, Patrick; Christian Viard-Gaudin; Dominique Barba (2006). "A Convolutional Neural Network Approach for Objective Video Quality Assessment". IEEE Transactions on Neural Networks. 17 (5): 1316–1327.
[5] Liang, J. and Qian, Y., 2008. Information granules and entropy theory in information systems. Science in China Series F: Information Sciences, 51(10), pp.1427-1444.
[6] De Boer, P.T., Kroese, D.P., Mannor, S. and Rubinstein, R.Y., 2005. A tutorial on the cross-entropy method. Annals of operations research, 134(1), pp.19-67.
[7] Vincent, P., Larochelle, H., Lajoie, I., Bengio, Y. and Manzagol, P.A., 2010. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 11(Dec), pp.3371-3408.
[8] Qian, G., Sural, S., Gu, Y. and Pramanik, S., 2004, March. Similarity between Euclidean and cosine angle distance for nearest neighbor queries. In Proceedings of the 2004 ACM symposium on Applied computing (pp. 1232-1237). ACM.